数据表设计
新增迁移文件:
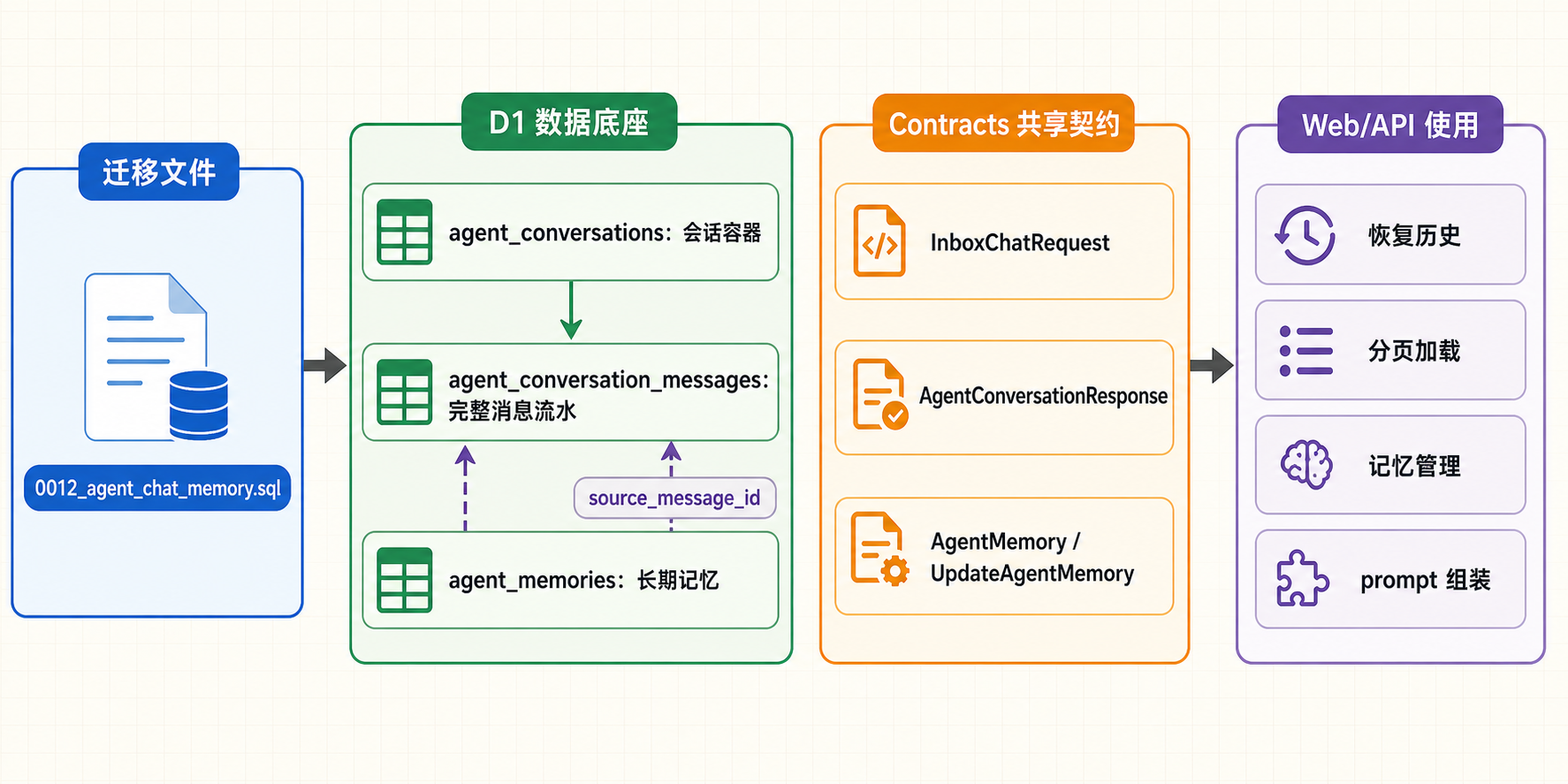
1apps/api/migrations/0012_agent_chat_memory.sql
这次新增了三张表。
这一篇只看数据底座。记忆系统后面的 API、prompt 组装、流式落库和前端恢复,最终都要落到这三张表和对应 contracts 上。表结构如果一开始没有把边界划清楚,后面业务代码就会慢慢变得模糊:消息到底属于谁、属于哪个 Agent、是否能追溯来源、记忆能不能停用、前端拿到的字段是否稳定,这些问题都会反复冒出来。
这里不是把字段堆得越全越好,而是先把几条基本关系固定下来。一个用户可以拥有多个 Agent;一个用户和一个 Agent 在 v1 里只有一个默认会话;一个会话下面有多条聊天消息;长期记忆属于某个用户和某个 Agent,并且可以追溯到来源消息。只要这几条关系稳定,后面的查询、权限校验和页面展示就会清楚很多。

我们也可以把这三张表看成三个层次。agent_conversations 管会话级信息,保存摘要、消息数和最近更新时间;agent_conversation_messages 管完整消息流水,保存用户消息和 assistant 回复;agent_memories 管长期记忆,保存被抽取出来的稳定信息。它们彼此有关联,但职责并不重叠。
从整体上看,这一篇其实是在建立一条从数据库到前后端契约的链路:迁移文件先创建数据底座,三张表分别承接会话、消息和长期记忆,contracts 再把这些后端数据整理成前端可以稳定使用的请求和响应结构。
1. agent_conversations
agent_conversations 是用户和某个 Agent 的默认会话主表。
01CREATE TABLE IF NOT EXISTS agent_conversations (02id TEXT PRIMARY KEY,03user_id TEXT NOT NULL REFERENCES users(id) ON DELETE CASCADE,04agent_id TEXT NOT NULL REFERENCES user_agent_companions(id) ON DELETE CASCADE,05title TEXT,06summary TEXT,07message_count INTEGER NOT NULL DEFAULT 0,08last_message_at_ms INTEGER,09created_at_ms INTEGER NOT NULL,10updated_at_ms INTEGER NOT NULL11);1213CREATE UNIQUE INDEX IF NOT EXISTS idx_agent_conversations_user_agent_unique14ON agent_conversations(user_id, agent_id);
这里用了 user_id + agent_id 唯一索引,代表 v1 只支持「一个用户和一个 Agent 有一个默认会话」。
summary 用来保存滚动摘要,message_count 用来记录消息数量,last_message_at_ms 用来给首页列表排序。
这张表的关键不是保存聊天正文,而是给一段聊天建立一个稳定容器。后面无论是恢复历史、分页加载消息,还是组装 prompt,都需要先知道当前用户和当前 Agent 对应的是哪一个 conversation。没有这张会话表,消息表就只能按 user_id + agent_id 直接查询,短期也能跑,但后续想支持多会话、会话标题、会话摘要、会话排序时就会比较被动。
id 是会话自己的主键。即使 v1 只有默认会话,也仍然需要这个字段,因为消息表要通过 conversation_id 关联到会话。这样做可以把当前的一对一默认会话和未来的多会话模型衔接起来。以后如果允许一个 Agent 有多段 conversation,消息表不需要推翻,只需要调整会话表的唯一约束和查询入口。
user_id 和 agent_id 同时存在,是为了让会话归属足够明确。我们不能只存 agent_id,因为 Agent 本身是用户资产的一部分,任何查询都要回到当前登录用户。如果只靠前端传来的 Agent ID 取数据,权限边界会变弱。把 user_id 写进会话表以后,每次查询都可以把用户和 Agent 一起作为条件,避免跨用户读取。
summary 是这张表里非常重要的字段。它保存的是更早聊天的滚动摘要,不是完整消息。完整消息放在消息表里,摘要放在会话表里,这样读取会话时就能快速拿到一份压缩上下文。它不会替代历史消息,但会参与后续 prompt 组装。
message_count 看起来像一个可由消息表统计出来的字段,但这里选择冗余保存,是为了让会话层能快速知道聊天规模。后续页面上可能要展示消息数量,也可能要根据消息数量决定何时更新摘要。如果每次都临时 count 消息表,在 D1 上不是不能做,但没有必要把这种高频信息完全交给实时聚合。
last_message_at_ms 则服务于列表排序。首页 Agent 列表需要知道哪个 Agent 最近发生过对话。这个字段放在 conversation 上,比每次联表取最新消息再排序更直接。它也能覆盖用户消息先落库、assistant 后回复的情况,只要有新消息进入,会话就能被更新到列表前面。
2. agent_conversation_messages
agent_conversation_messages 保存完整聊天消息。
01CREATE TABLE IF NOT EXISTS agent_conversation_messages (02id TEXT PRIMARY KEY,03conversation_id TEXT NOT NULL REFERENCES agent_conversations(id) ON DELETE CASCADE,04user_id TEXT NOT NULL REFERENCES users(id) ON DELETE CASCADE,05agent_id TEXT NOT NULL REFERENCES user_agent_companions(id) ON DELETE CASCADE,06role TEXT NOT NULL CHECK (role IN ('user', 'assistant')),07content TEXT NOT NULL,08status TEXT NOT NULL CHECK (status IN ('completed', 'failed')),09metadata_json TEXT,10created_at_ms INTEGER NOT NULL11);
这张表里,conversation_id 用来关联会话,user_id 和 agent_id 冗余保存,方便后续查询和权限校验。role 当前只允许 user 和 assistant,status 预留失败态,后续可以保存失败消息或重试信息。metadata_json 则先留给 token 用量、模型名、provider 等扩展信息。
消息表是记忆系统最基础的数据来源。它保存的是完整聊天流水,不能只保存 assistant 回复,也不能只保存最后一条消息。用户说了什么、assistant 怎么回答、消息什么时候产生、是否成功完成,这些信息都要保留下来,后面才能恢复历史,也才能从历史中抽取长期记忆。
这里保留了 conversation_id,同时也冗余了 user_id 和 agent_id。从范式上看,user_id 和 agent_id 可以通过 conversation 查出来,但实际业务里冗余它们有明显好处。第一是查询方便,很多场景会直接按用户和 Agent 查消息;第二是权限校验更直接,不需要每次都先查 conversation 再查 messages;第三是后续排查数据时更清楚,单看消息表就能知道消息属于谁和哪个 Agent。
role 当前只允许 user 和 assistant,这和当前产品形态一致。系统 prompt、工具调用、中间状态这些内容没有直接进入消息表。这样做能让页面恢复历史时更干净,因为前端真正要展示的就是用户消息和 assistant 回复。以后如果要保存 tool message 或 system message,可以再评估是否扩展 role,或者另建一张更偏执行轨迹的表。
status 当前主要是 completed,但预留了 failed。这个字段很有必要。聊天链路里可能出现一种情况:用户消息已经写入,LLM 调用失败,assistant 没有成功返回。此时我们仍然希望用户消息保留在历史里,也希望后续有能力展示失败态、提供重试入口,或者分析失败原因。没有 status,消息表就只能表达「存在」,很难表达「这条消息没有完成」。
metadata_json 是给后续扩展准备的。第一版不急着把 token 用量、模型 provider、延迟、请求 ID 这些信息都拆成字段,但完全没有预留也会限制后续分析。用 JSON 字段先放扩展信息,能在不频繁改 schema 的情况下承接一些非核心数据。等某些字段稳定成为查询条件,再考虑单独升成列。
created_at_ms 用毫秒时间戳保存创建时间,这对分页尤其重要。当前分页游标用最早消息的 createdAtMs,也就是从时间上继续向前翻。毫秒级时间通常已经足够,但极端情况下同一毫秒可能产生多条消息,所以后续可以把游标升级成 createdAtMs + id 的组合。这个点在表结构里提前有 id 和时间字段,后面就有优化空间。
3. agent_memories
agent_memories 保存长期记忆。
01CREATE TABLE IF NOT EXISTS agent_memories (02id TEXT PRIMARY KEY,03user_id TEXT NOT NULL REFERENCES users(id) ON DELETE CASCADE,04agent_id TEXT NOT NULL REFERENCES user_agent_companions(id) ON DELETE CASCADE,05type TEXT NOT NULL,06content TEXT NOT NULL,07importance INTEGER NOT NULL DEFAULT 3,08status TEXT NOT NULL CHECK (status IN ('active', 'disabled', 'deleted')),09source_message_id TEXT REFERENCES agent_conversation_messages(id) ON DELETE SET NULL,10created_at_ms INTEGER NOT NULL,11updated_at_ms INTEGER NOT NULL12);
长期记忆并不是一段纯文本数组,而是结构化数据:
type:记忆类型,比如偏好、边界、关系目标。content:记忆内容。importance:重要度,1 到 5。status:启用、停用、删除。source_message_id:来源消息,方便在记忆库里追溯。
长期记忆和聊天消息不是同一种东西。消息是对话原文,记忆是从对话里抽取出来的稳定信息。如果把长期记忆也当成一段消息保存,后续就很难管理它的类型、重要度和状态。比如用户说过一句「以后回复我尽量直接一点」,这句话作为消息会留在历史里;但作为长期记忆,它应该被归类为偏好,并且在后续聊天中优先参与 prompt。
type 用来表达记忆类型。当前可以是偏好、边界、关系目标、对话风格这类文本值。这里没有直接做成枚举,是为了给第一版留一点弹性。因为记忆类型可能会随着产品理解继续调整,如果一开始就把类型锁死,后面每次增加类型都要改数据库约束和前后端枚举。当然,contracts 里仍然会限制字符串长度,避免写入过长内容。
content 是真正注入 prompt 的记忆内容。它需要足够短,不能把一大段聊天原文原封不动塞进去。长期记忆的价值在于提炼,而不是复制。内容越清晰,后续越容易展示给用户,也越容易被模型稳定理解。
importance 是一个排序依据。第一版没有语义检索,所以长期记忆进入 prompt 时主要按重要度和更新时间取前几条。重要度越高,越应该优先注入。比如用户明确说「不要用套路化话术」这种边界信息,重要度就应该高于普通聊天偏好。
status 也需要认真处理,因为记忆需要可管理。用户可能觉得某条记忆不准确,或者某个偏好已经变化。直接物理删除虽然简单,但会失去审计和恢复空间。所以这里支持 active、disabled、deleted。active 会参与 prompt;disabled 暂时不参与,但数据还在;deleted 表示用户删除,页面不再展示为有效记忆。
source_message_id 让记忆可以追溯来源。记忆系统最怕的一件事是用户不知道某条记忆从哪里来的。如果页面上能看到来源消息,用户就能判断这条记忆是否抽取得准确。即使第一版页面没有把来源展示得很完整,表结构里先把这个关联保留下来,后续迭代就不会缺数据。
Contracts 扩展
前后端共享契约在 contracts 包里。
聊天请求新增了 conversationId,并且 conversation.id 作为 Agent ID 传入。
表结构只是后端存储模型,前端真正接触到的是 contracts。这个项目里前后端共用 contracts 包,所以每次新增记忆系统能力,都要把请求和响应结构同步定义清楚。这样 web 子站发请求时有类型约束,api 子站返回数据时也能通过 schema 做校验。
conversationId 是这次聊天请求里最重要的新增字段之一。之前聊天请求只需要把当前 UI 消息和聊天对象资料传给 API,现在有了服务端会话以后,请求必须告诉后端这条消息要落到哪个 conversation 里。这个字段是可选的,是为了兼容一些还没有会话上下文的边缘路径,但正常 Agent 聊天应该带上它。
conversation.id 作为 Agent ID 传入,是因为前端的聊天对象本身就是当前 Agent。后端会用它找到用户拥有的 Agent,再找到或创建默认会话。这里不能只相信前端传来的对象资料,因为 name、handle、profileNote 这些都可以被客户端构造;真正的权限判断一定要回到服务端数据库。
01// packages/contracts/src/chat/inbox-chat.contract.ts02export const InboxChatRequestSchema = z.object({03conversationId: z.string().min(1).optional(),04messages: z.array(InboxChatMessageSchema).min(1).max(20),05llmConfig: InboxChatLlmConfigSchema.optional(),06conversation: z.object({07id: z.string().min(1).optional(),08name: z.string().min(1).max(120),09handle: z.string().min(1).max(120),10headline: z.string().min(1).max(200),11lastActive: z.string().min(1).max(80),12status: z.string().min(1).max(80),13relationship: z.string().min(1).max(120),14topic: z.string().min(1).max(120),15chemistry: z.string().min(1).max(80),16chemistryLabel: z.string().min(1).max(80),17rhythm: z.string().min(1).max(80),18profileNote: z.string().min(1).max(2000),19imageKey: z.string().nullable().optional(),20}),21})
历史会话响应也定义在这里:
01export const AgentConversationMessageSchema = z.object({02id: z.string().min(1),03conversationId: z.string().min(1),04agentId: z.string().min(1),05role: z.enum(['user', 'assistant']),06content: z.string(),07status: z.enum(['completed', 'failed']),08createdAtMs: z.number().int().nonnegative(),09})1011export const AgentConversationResponseSchema = z.object({12conversationId: z.string().min(1),13agentId: z.string().min(1),14title: z.string().nullable(),15summary: z.string().nullable(),16messageCount: z.number().int().nonnegative(),17openingMessage: z.string().nullable(),18messages: z.array(AgentConversationMessageSchema),19nextCursor: z.string().nullable(),20})
记忆管理的契约在 Agent 相关 contract 里:
历史会话响应里的 messages 是页面恢复聊天窗口的核心数据。nextCursor 则服务于加载更早消息。如果它是 null,说明没有更多历史;如果有值,前端就可以继续请求分页接口。openingMessage 也放在响应里,是为了让前端在没有历史消息时仍然能展示 Agent 的默认开场。
记忆相关 contract 则服务于记忆库页面。AgentMemorySchema 里不仅有记忆本身的 type、content、importance 和 status,还保留了 sourceMessage。这让页面后续可以展示「这条记忆来自哪条对话」。UpdateAgentMemoryRequestSchema 则限制了用户可以修改的范围:可以改类型、内容、重要度和状态,但不能改归属关系,也不能随意改来源消息。
Contracts 的价值在这里会慢慢体现出来。记忆系统跨越 api、web、contracts 三个部分,如果没有共享契约,字段名和类型很容易漂移。比如后端返回 createdAtMs,前端却按 created_at_ms 读取,页面就会出现隐蔽 bug。把这些结构集中在 contracts 里,等于给前后端之间立了一份稳定协议。
01// packages/contracts/src/agent/my-summary.contract.ts02export const AgentMemorySchema = z.object({03id: z.string().min(1),04agentId: z.string().min(1),05type: z.string().min(1).max(80),06content: z.string().min(1).max(2000),07importance: z.number().int().min(1).max(5),08status: z.enum(['active', 'disabled', 'deleted']),09sourceMessageId: z.string().nullable(),10sourceMessage: z.object({11id: z.string().min(1),12role: z.enum(['user', 'assistant']),13content: z.string(),14createdAtMs: z.number().int().nonnegative(),15}).nullable(),16createdAtMs: z.number().int().nonnegative(),17updatedAtMs: z.number().int().nonnegative(),18})1920export const UpdateAgentMemoryRequestSchema = z.object({21type: z.string().trim().min(1).max(80).optional(),22content: z.string().trim().min(1).max(2000).optional(),23importance: z.number().int().min(1).max(5).optional(),24status: z.enum(['active', 'disabled']).optional(),25})
总结
这一篇把记忆系统的数据底座先铺出来了。agent_conversations 负责承载一段会话,agent_conversation_messages 保存完整聊天流水,agent_memories 保存可以长期复用的结构化记忆。Contracts 则把这些后端数据转换成前端能稳定使用的请求和响应结构。表结构和契约先清楚,后面的历史 API、prompt 组装和记忆库页面才不会散。