背景
Agent 聊天记忆系统实现:从聊天历史到长期记忆
这一组文章会围绕 Agent 聊天记忆系统的完整实现展开,从聊天历史持久化,一直讲到长期记忆沉淀。
在没有记忆系统之前,Agent 聊天只有一次性的前端内存状态。
用户在首页聊天框里发送消息时,web 端会把当前 messages 直接发给 api 子站的 /rpc/chat/inbox。api 子站调用 LLM 后,把流式文本返回给前端。整个过程看起来能聊天,但有一个明显问题:刷新页面以后,历史对话就没了。
更进一步说,之前系统只更新了 Agent 列表里的 last_assistant_message,用于首页列表展示「最新回复」。但真正的用户消息、AI 回复、历史上下文、长期偏好,都没有持久化。
这会让聊天产品停留在比较浅的一层。用户刚刚和某个 Agent 说过的话,只存在当前页面的状态里;浏览器刷新、切换页面、重新打开首页,这些内容就不再可靠。对普通表单来说,这可能只是状态丢失;但对聊天产品来说,这会直接破坏连续感。用户会自然期待 Agent 记得上一轮说过什么,至少能恢复刚才那段对话,而不是每次都像第一次见面。
还有一个更隐蔽的问题:没有历史消息,就很难做真正的上下文注入。前端把当前 messages 传给接口,短时间内看起来还能保持对话连贯,但这套上下文完全依赖浏览器当前状态。一旦页面状态重建,后端就失去了判断依据。对于一个 Agent 系统来说,记忆能力不能只绑在 UI 上,它应该沉到服务端的数据结构里,变成可以查询、可以分页、可以管理、可以参与 prompt 组装的业务能力。
因此我们这次不是简单给聊天窗口加一个 localStorage 缓存,而是给 Agent 聊天建立一套服务端记忆系统。它要保存消息,也要知道这些消息属于哪个用户、哪个 Agent、哪一段会话;它要能恢复最近历史,也要能让用户继续加载更早的消息;它还要把稳定偏好、边界和关系目标沉淀成长期记忆,而不是每次都从完整聊天记录里重新推断。
这次要实现的是一个 v1 版本的 Agent 聊天记忆系统。它会保存完整聊天历史,让用户重新打开 Agent 时能恢复之前的消息;历史内容变多以后,也可以继续分页加载更早的对话。聊天时,后端会把最近消息、滚动摘要和长期记忆一起用于 prompt 组装。等聊天成功以后,系统还会从本轮对话里沉淀轻量长期记忆,并且在记忆库页面里提供查看、编辑、停用和删除能力。
我们会按真实项目实现,把设计思路和关键实现慢慢拆开讲清楚。
我们可以先把目标放得更具体一点。第一版要解决的是产品闭环,不是一上来就追求最复杂的记忆算法。只要用户刷新页面后还能看到历史,继续聊天时后端能拿到最近上下文,Agent 能根据少量长期记忆调整回答,记忆库页面能让用户看见和管理这些记忆,这套能力就已经从一次性聊天升级成了可以积累上下文的聊天系统。
整体设计
第一版没有引入向量数据库,也没有上复杂的 RAG 检索。原因很简单:当前产品还处在 Agent 一对一聊天的早期阶段,D1 已经足够支撑「历史消息 + 摘要 + 少量长期记忆」。
这里的设计重点是分层,而不是堆能力。聊天历史、会话摘要、长期记忆看起来都在解决「让 Agent 记住东西」这件事,但它们的职责并不一样。如果把所有消息都直接塞进 prompt,短期内最省事,后面很快会遇到上下文越来越长、请求越来越慢、成本越来越高的问题。如果只保存一段摘要,又会丢掉最近对话里的细节,比如用户刚刚问的问题、上一句 assistant 的回答、刚刚确认过的上下文。
因此我们把记忆拆成三层。最近消息负责保留对话现场,会话摘要负责压缩更早内容,长期记忆负责记录那些跨多轮对话仍然稳定有效的信息。这样每一层都只做自己最适合的事情,系统也更容易维护。
最终采用的是三层记忆结构:
1短期上下文:最近 18 条聊天消息2↓3中期上下文:conversation.summary 滚动摘要4↓5长期记忆:agent_memories 结构化记忆
这三层记忆不是孤立存在的。一次真实聊天里,后端会先拿到本轮用户输入,再读取最近消息、会话摘要和长期记忆,把它们一起组装进 prompt;等 LLM 回复完成以后,新的消息和可能沉淀出的长期记忆还会再写回数据库。
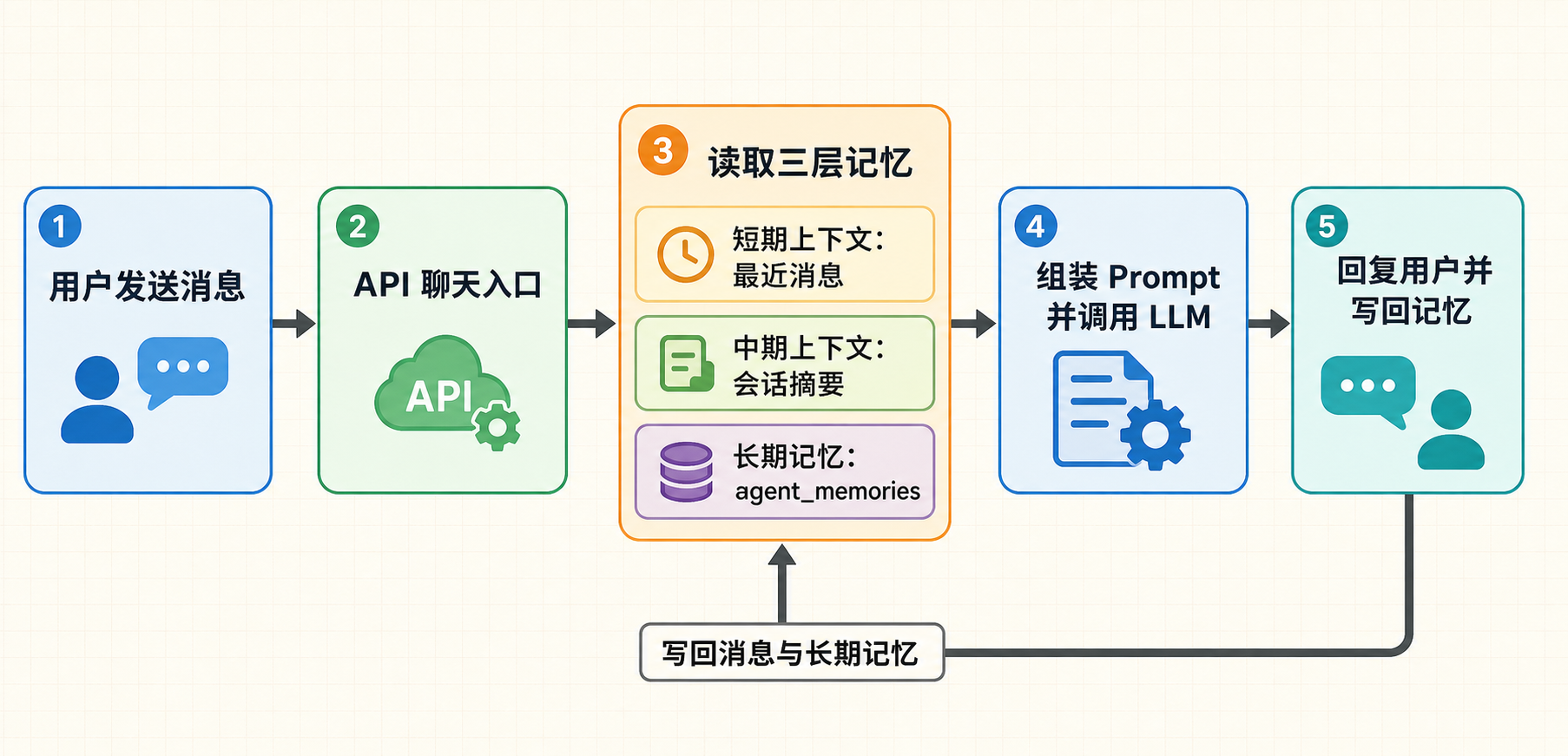
聊天时 prompt 的注入顺序是:
11. Agent 默认人设 prompt22. 用户与该 Agent 的长期记忆33. 会话摘要44. 最近聊天消息55. 本轮用户输入
这样拆开以后,每一层记忆都有自己的位置。最近消息负责保证对话连贯,摘要负责压缩更早的上下文,长期记忆负责保存偏好、边界、关系目标这些更稳定的事实。第一版暂时不依赖向量库,部署和迁移也会轻一些。
我们可以逐层看一下。
短期上下文通常是最可靠的。它直接来自最近聊天消息,语义没有经过压缩,也没有被抽象成标签。用户刚刚说的话、assistant 刚刚给过的建议、当前话题正在讨论到哪一步,都应该从最近消息里拿。这里选择最近 18 条,是一个比较务实的折中:太少会让对话跳跃,太多会挤占 prompt 空间。这个数字后续可以调整,但第一版先给一个明确上限,能让请求体和模型上下文保持可控。
中期上下文使用 conversation.summary。它不是为了替代完整历史,而是为了保存更早对话的大概脉络。比如用户和某个 Agent 已经聊过几轮关系阶段、沟通风格、最近遇到的困扰,这些内容不一定每次都需要原文进入 prompt,但完全丢掉又会让 Agent 的回答显得断裂。摘要就是在这两者之间做一个压缩,让较早的上下文以更轻的形式继续参与对话。
长期记忆则更像用户和某个 Agent 之间的稳定档案。它记录的不是某一轮对话,而是可以长期影响回答方式的信息。例如用户不喜欢被过度解读,用户希望回复更自然直接,用户正在尝试维持某种关系边界,这些内容适合沉淀到 agent_memories。下次聊天时,即使最近消息里没有提到这些点,Agent 仍然可以优先尊重这些记忆。
这三层合在一起,才是完整的记忆系统。只保存最近消息,能恢复历史,但无法形成长期偏好。只保存长期记忆,又会丢掉当前对话现场。只保存摘要,则细节会不够稳定。三层同时存在以后,聊天系统既能延续当前话题,也能保留更早脉络,还能记住那些用户明确表达过的偏好和边界。
还有一个设计原则需要提前放清楚:记忆要能被管理。长期记忆如果只是后端悄悄写入,再悄悄影响 prompt,用户会很难判断 Agent 为什么这样回答。所以第一版就安排了记忆库页面,让用户可以查看、编辑、停用和删除记忆。这样记忆不再是黑盒,而是产品里可以被用户感知和控制的一部分。
第一版先解决闭环
做记忆系统时,很容易一开始就想得很大:要不要 embedding,要不要多会话,要不要记忆确认,要不要自动总结,要不要做语义检索。这些方向都合理,但如果第一版同时铺开,代码会很快变复杂,真正能跑通的产品体验反而会被推迟。
因此这一版先把闭环收住。用户发送消息后,用户消息要先落库;assistant 回复完成后,assistant 消息要落库;打开 Agent 时,要能从服务端恢复历史;历史太多时,要能分页加载更早消息;聊天完成后,要能沉淀一些轻量长期记忆;用户打开记忆库时,要能看到这些记忆,并且可以修改或停用。
这几个能力看起来朴素,但它们构成了记忆系统的基础骨架。没有消息落库,就谈不上会话恢复。没有会话恢复,前端聊天窗口就只能依赖临时状态。没有长期记忆,就无法让 Agent 在多次对话之间保留偏好。没有管理页面,用户就无法理解和控制系统记住了什么。
第一版不是要证明我们能做一个多复杂的智能记忆系统,而是要证明这套产品有了可以持续积累上下文的能力。等这个闭环稳定以后,再升级 LLM 摘要、记忆确认和向量检索,就会有清晰的落点。
为什么不一开始就上向量数据库
很多人一听到「记忆系统」,第一反应就是 embedding 和向量检索。
但这个项目当前阶段没有直接上向量库。当前还是用户与单个 Agent 的一对一聊天,数据规模没有大到必须做语义检索。长期记忆本身也是结构化短文本,先按重要度和更新时间取前几条,已经足够支撑第一版体验。再加上 D1 的迁移、部署和调试成本更低,更适合先把产品闭环跑通。
现在的 agent_memories 表其实已经为后续向量化预留了空间。未来可以增加:
1embedding_id TEXT2embedding_model TEXT3embedded_at_ms INTEGER
或者新建一张 memory embedding 表,再接 Cloudflare Vectorize 或其他向量数据库。
这里并不是否定向量数据库的价值。等长期记忆数量变多以后,只按重要度和更新时间取前几条,确实会不够精确。比如用户已经积累了几十条记忆,本轮输入只和其中两三条相关,如果仍然把最高重要度的几条拿出来,可能会漏掉当前语义最贴近的记忆。向量检索正是为了解决这种相关性问题。
但在当前阶段,直接上向量库会带来额外复杂度。我们要考虑 embedding 模型、向量写入、失败重试、索引更新、部署绑定、成本控制,以及记忆内容被编辑或删除以后向量如何同步。对于一个刚要把聊天历史和长期记忆跑通的产品来说,这些复杂度会分散注意力。
D1 的优势是简单、可控、容易迁移。三张表就能把会话、消息、长期记忆组织起来;查询逻辑也比较直观;本地开发和远程部署都可以跟现有 API 子站保持一致。第一版先用 D1 跑通产品闭环,不会阻碍后续接入向量库,反而能让后续升级有更明确的数据基础。
所以这一篇我们先把设计边界定下来:第一版记忆系统用 D1 解决历史持久化、摘要压缩和结构化长期记忆。向量检索不是不做,而是在记忆数量、查询复杂度和产品需求真正上来以后再做。这样节奏会更稳,也更适合这个项目当前阶段。
总结
Agent 聊天记忆系统第一版要解决的,不是复杂算法,而是让聊天真正有连续性。最近消息保留当前对话现场,会话摘要承接更早的上下文,长期记忆沉淀稳定偏好和边界。我们先用 D1 把这套基础能力跑通,让历史可恢复、上下文可注入、记忆可管理。后面再继续升级 LLM 摘要、记忆确认和向量检索,就会更有依据。